We use cookies to ensure that we give you the best experience on our website. By continuing to use the website you agree for the use of cookies for better website performance and a personalized experience.
Apache Druid vs. Google BigQuery: Cost, Performance & Analytics Comparison
Christina Kosteva
.
September 26, 2025
Christina Kosteva
September 26, 2025
.
X MIN Read
September 26, 2025
.
X MIN Read
September 26, 2025
.
X MIN Read
Selecting the right analytics platform is pivotal for organizations seeking actionable insights from their data. Apache Druid and Google BigQuery are two prominent choices, each tailored for high-performance analytics but with distinct strengths. This article provides a detailed comparison of their architecture, scalability, performance, and costs, helping you determine which platform best meets your needs. We also present real-world cost scenarios to highlight their financial implications.
Apache Druid Overview
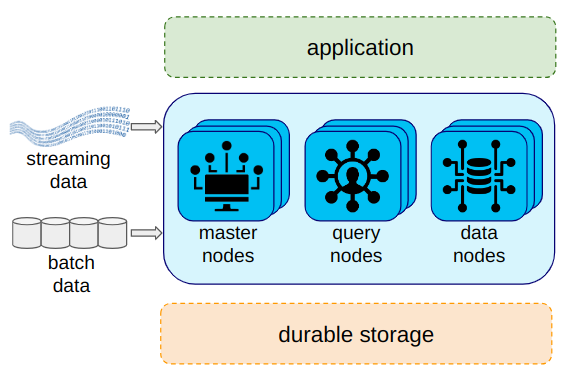
Apache Druid is a high-performance analytics database optimized for low-latency, high-concurrency queries on both streaming and historical data. Its architecture bridges batch and real-time processing, making it highly customizable and scalable.
Key Features of Apache Druid:
Interactive Analytics: Sub-second response times for high-concurrency use cases
Kappa Architecture: Blends real-time and batch processing seamlessly
Optimized Storage and Compute: Minimizes data movement for reduced latency
Open Source and Extensible: A community-driven project used by over 2,000 enterprises
User Activity Monitoring: Real-time insights into user behavior
Network Flow Analytics: High-cardinality metrics across dozens of attributes
Digital Marketing: Tracking impressions, clicks, and conversion rates
Google BigQuery Overview
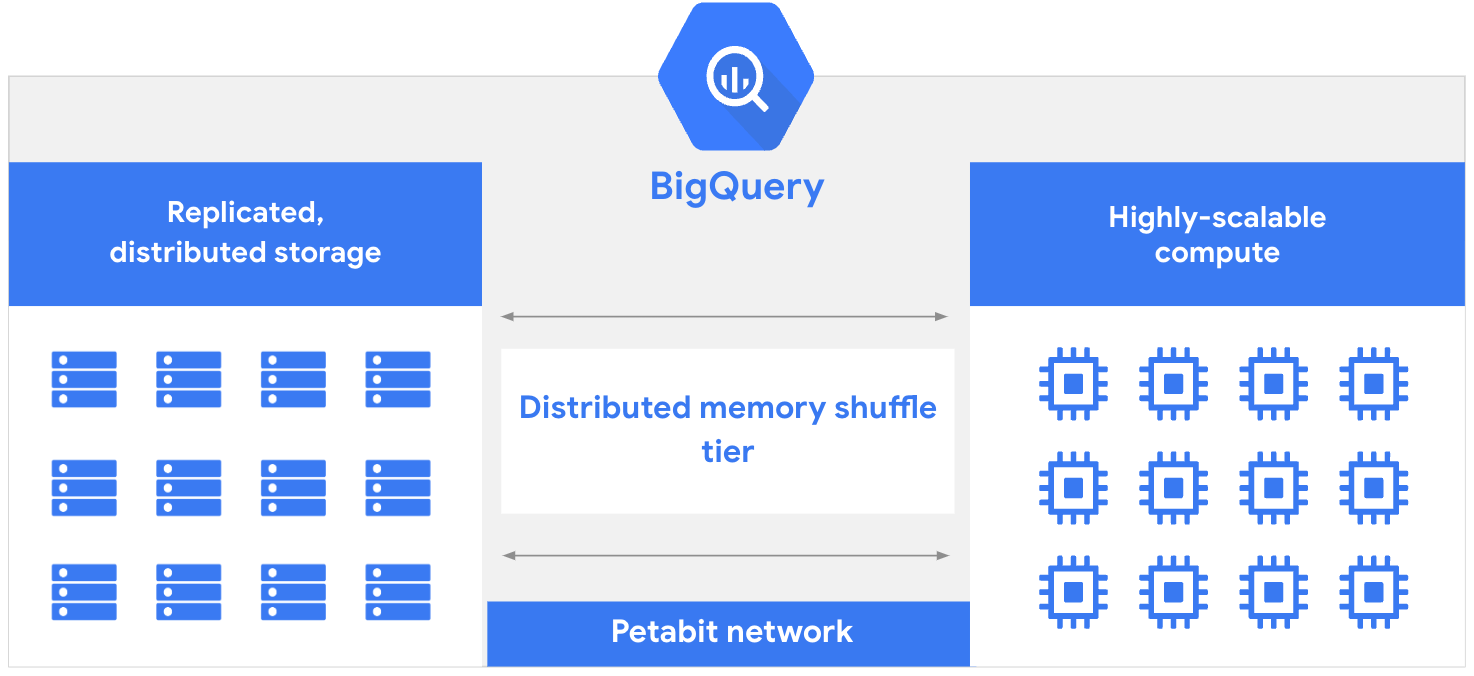
Google BigQuery is a fully managed, serverless data warehouse optimized for handling massive-scale analytical workloads. It offers seamless integration with the Google Cloud Platform (GCP) ecosystem and emphasizes ease of use with SQL-based querying.
Separation of Compute and Storage: Independent scaling for flexibility
Built-in Machine Learning: Facilitates predictions and advanced analytics
Data Transfer Service: Consolidates data from various external sources
Typical Use Cases:
Classic Business Intelligence: Ad hoc reporting and analytics.
Streaming ingestion pipelines: Near real-time, but not millisecond-latency
Machine Learning on GCP: Seamless integration for advanced analytics
Key Differences Between Apache Druid and Google BigQuery
Feature
Apache Druid
Google BigQuery
Architecture
Clustered, with role-specific nodes
Serverless, decoupled compute and storage
Cloud Support
Any cloud or on-premise
Google Cloud only
Latency
Sub-second
Typically seconds to tens of seconds
Concurrency
High (thousands of users)
Limited by default (100 concurrent queries/project, expandable with slots)
Real-Time Ingestion
Supported
Not natively supported
Query Language
Native JSON and SQL
SQL and extensions
Cost Model
Infrastructure + optional support
Usage-based (scales with data volume & queries)
Detailed Comparison of Key Aspects
1. Architecture
Aspect
Apache Druid
Google BigQuery
Architecture Type
Clustered with specialized servers
Serverless with decoupled storage and compute
Supported Cloud Infrastructure
Any cloud or on-premises
Google Cloud only
Control of Compute
Complex configuration of compute tiers with role-specific nodes and a configurable number of nodes.
Fully managed serverless model; BigQuery allocates "slots" per query, with no user control.
Hosting Options
Self-hosted or SaaS
Only SaaS (pay-as-you-go)
Uses Storage Format
Columnar format with time-based sorting
Compressed columnar format called Capacitor
Insights:
Apache Druid offers fine-grained control, allowing tailored infrastructure setups for specialized use cases. This is ideal for organizations with custom needs or hybrid cloud requirements. Google BigQuery, on the other hand, abstracts away infrastructure, favoring ease of use and tight integration with the GCP ecosystem.
2. Performance
Aspect
Apache Druid
Google BigQuery
Low Latency
Yes, sub-second latency at scale and under load
No, tens of seconds at a 100 GB scale
High Concurrency
Yes, handling thousands of concurrent users
No, limited concurrent queries
Real-Time Ingestion
Yes, native support
No, only available streaming data in batch mode
Complex Query Support (windows, joins, etc.)
Limited, some operations are possible, but not possible to optimize entirely
Yes, fully supports SQL and extensions
Available Caching
Two types of caching: per-segment caching for storing partial query result and whole-query caching to cache entire query result
Whole-query caching result: requires the query text to be identical to the original query for data to be retrieved from the cache
Built-in Query Language
Native query language (JSON) and SQL support
SQL and extensions for advanced query use cases
Insights:
Apache Druid excels in low-latency, high-concurrency workloads with real-time ingestion capabilities. BigQuery, with strong support for complex queries, is better suited for less time-sensitive analytics but may struggle under heavy concurrent loads or low-latency requirements.
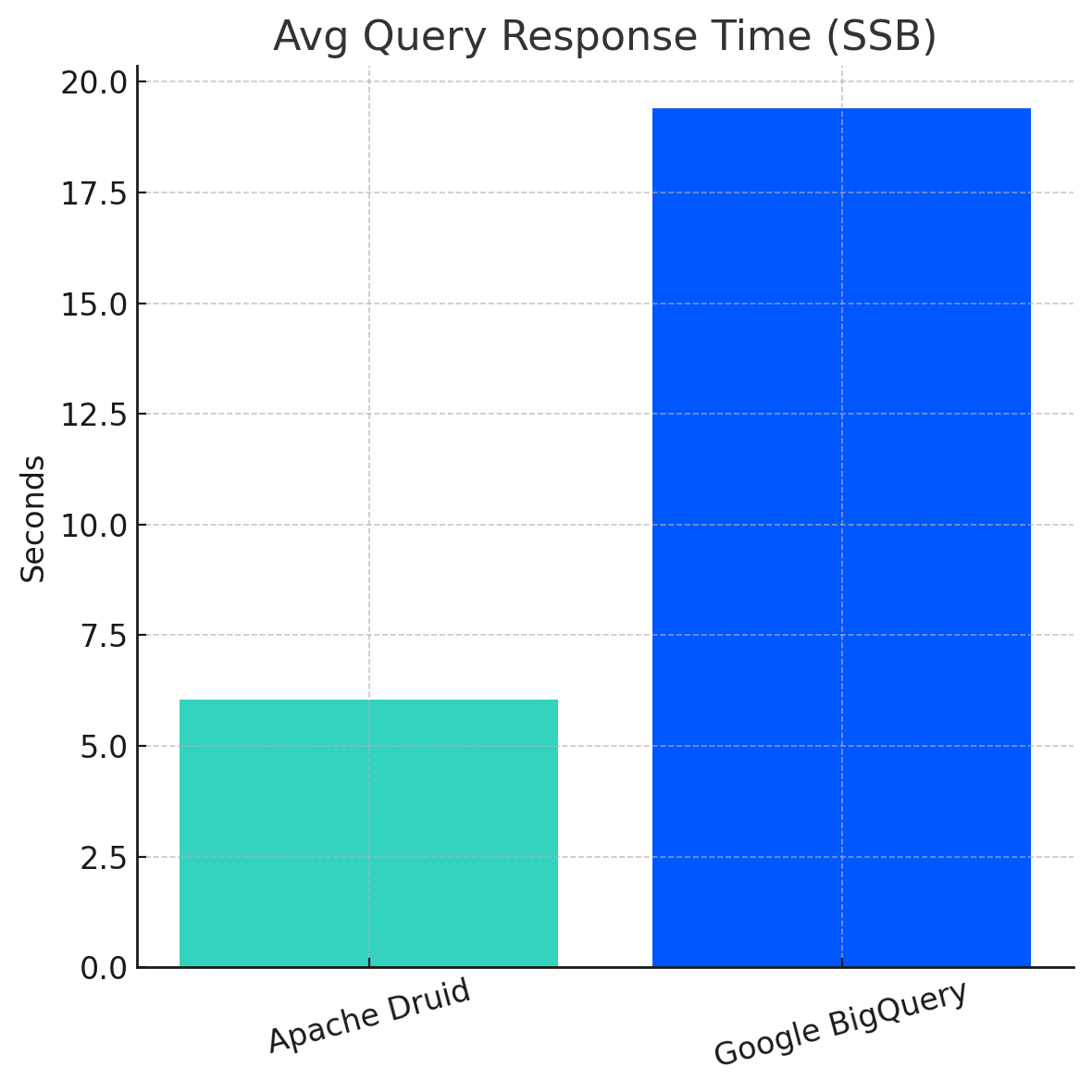
Star Schema Benchmark (SSB)
The Star Schema Benchmark (SSB) evaluates analytics database performance using 13 standardized SQL queries. In this research by Imply, Apache Druid outperformed Google BigQuery significantly in both response time and cost-effectiveness:
Query Response Time:
Apache Druid: 6.04 seconds (average)
Google BigQuery: 19.4 seconds (average)
Result: Druid is 321% faster.
Cost Advantage:
Apache Druid offers a 12x price-performance advantage.
Example Scenario: For high concurrency, Druid can save up to $194,600/month.
3. Scalability
Aspect
Apache Druid
Google BigQuery
Scaling Data Volume
Horizontally scalable by adding nodes to the cluster.
Automatically scales with increasing storage needs.
Increasing Concurrency and Number of End-Users
Possible but depending on such factors as segment size, number of cores, memory size, etc.
Not possible, default fixed cap on concurrent queries.
Insights:
Apache Druid provides flexibility in scaling both data volume and user concurrency, though it requires expertise in configuration and management. Google BigQuery scales data storage effortlessly but faces limits on concurrency, which could be a bottleneck for high-demand workloads.
4. Cost Comparison
Cost evaluation is often a deciding factor, especially for organizations with high query volumes or complex analytics needs. Below, we analyze costs using an exemplary medium-size cluster and the following example use case:
Scenario
The average monthly cost is calculated based on:
Data Volume: 5 TB of stored data
Query Pattern: 3 queries per second, each querying 5 GB of data (0.1% of the total dataset)
Average Query Duration: 10 seconds
Timeframe: Costs are calculated on a monthly and annual basis
Apache Druid Costs
Infrastructure for an example medium-sized cluster (AWS Example):
Master Nodes: 2 x r5a.large = $160/month
Query Nodes: 2 x r5d.xlarge = $420/month
Real-Time Nodes: 3 x r5ad.xlarge = $570/month
Historical Nodes: 3 x i3.4xlarge = $2,700/month
Deep Storage: 5 TB on S3 = $125/month
Total Monthly Infrastructure Cost: $3,975 Total Annual Infrastructure Cost: $47,700
Support and Maintenance (Optional):
24/7 SLA engineer-led support from Deep.BI for up to 25 nodes
DevOps, performance tuning, and maintenance
$195,000/year*.
*Please note: This is an example price. For your specific use case and requirements, please contact us to receive an exact pricing proposal.
Total annual costs
Service
Annual Cost
Infrastructure
$47,700/year
Support & Maintenance (Optional)
$195,000/year
Total with Support
$242,700/year
Google BigQuery Costs
The cost of using Google BigQuery depends primarily on two major factors:
Analysis pricing: Costs are incurred based on the volume of data scanned during SQL queries, user-defined functions (UDFs), and DML/DDL operations. This model scales linearly with data usage, making frequent or large-scale queries increasingly expensive.
Storage pricing: Based on the amount of active or long-term data stored in BigQuery tables.
Monthly Storage Costs
BigQuery charges a flat rate of $0.02 per GB per month for active storage. More details can be found here.
Total monthly query cost: 38,880 × $5 = $194,400/month
Total annual query cost: $2,332,800
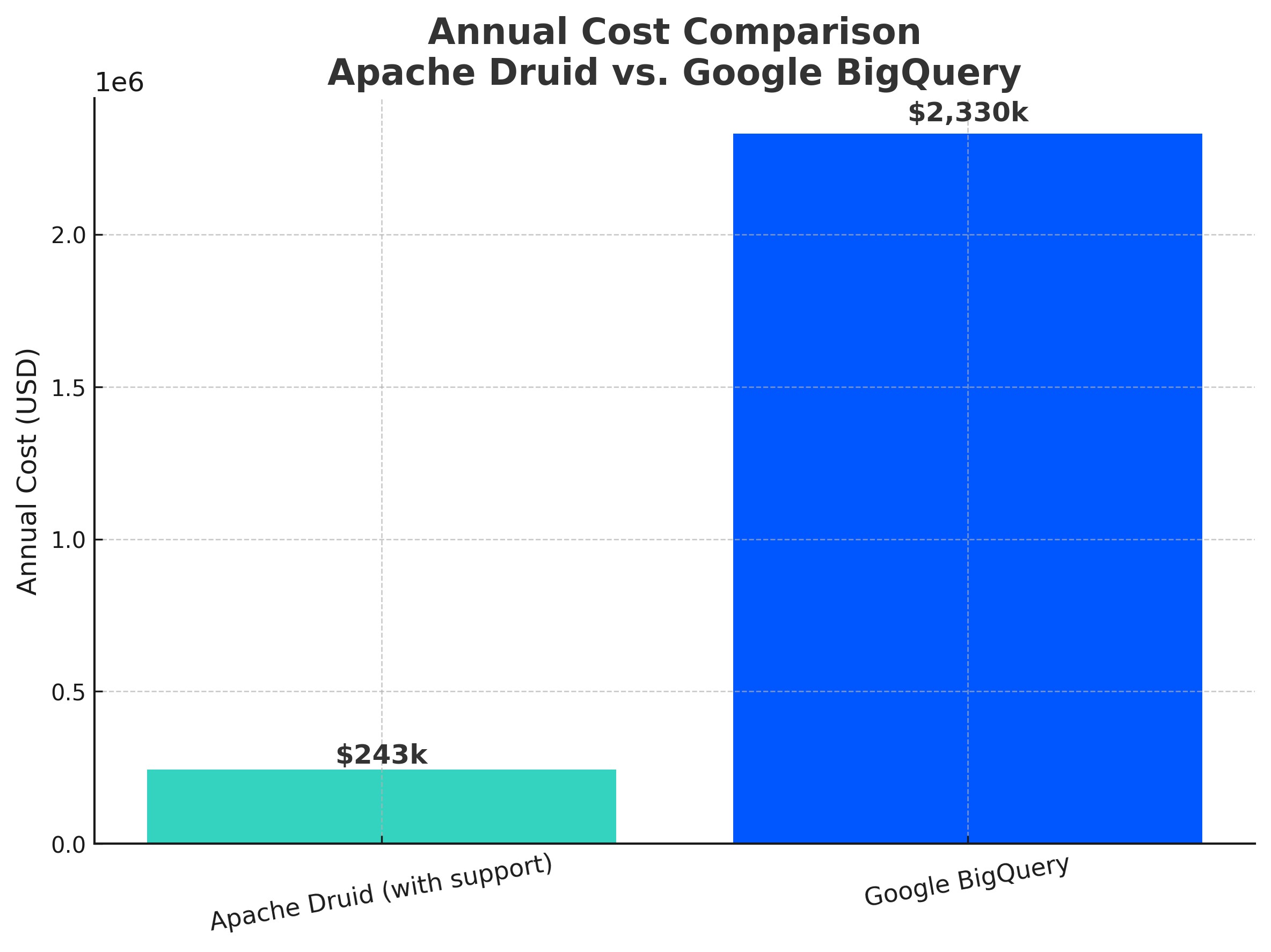
Annual Cost Comparison
Database Technology
Annual Cost
Google BigQuery
$2,334,000/year
Apache Druid (with support)
$242,700/year
Key Observations on Costs
Druid’s Cost Advantage: Apache Druid shows a 12x price-performance advantage over BigQuery in this scenario, saving over $2 million annually.
Operational Complexity: Druid requires expertise to manage infrastructure and optimize performance, which is why support costs are included in the analysis. BigQuery’s simplicity comes at a higher operational cost, particularly for query-intensive workloads.
Workload Sensitivity: BigQuery’s usage-based model causes costs to scale linearly with data volume and query frequency. While this serverless approach simplifies infrastructure management, it may lead to substantial expenses for data-intensive, high-frequency use cases.
Note: Actual costs can vary based on specific configurations, usage patterns, and regional pricing. It's advisable to use the respective platforms' pricing calculators for precise estimates.
5. Use Cases
Use Case
Apache Druid
Google BigQuery
Real-Time Analytics
Ideal for real-time dashboards and streaming data.
Supports batch ingestion of streaming pipelines.
Business Intelligence
Best for interactive OLAP workflows.
Better suited for complex ad hoc queries.
High Concurrency Dashboards
Efficiently serves thousands of simultaneous users.
Limited by default concurrency caps.
Machine Learning
Integrates with BI tools for feature extraction.
Embedded machine learning tools for predictions.
Conclusion: Which Platform Should You Choose?
Choose Apache Druid if:
Low latency and high concurrency are critical for your use case
Real-time data ingestion is a key requirement
You need cost-efficient analytics at scale
Choose Google BigQuery if:
You prefer serverless simplicity and tight integration with GCP
Your workload emphasizes ad hoc querying over real-time analytics
Cost is less of a concern than ease of use
Let Us Help You
Navigating analytics platforms requires deep expertise. At Deep.BI, we specialize in technologies such as Apache Druid, StarRocks, TiDB, ClickHouse, and Flink — helping enterprises build scalable, real-time data architectures.
We provide 24/7 support, performance tuning, and tailored solutions to maximize ROI on your data strategy. Contact us to explore how we can help unlock the full potential of your analytics stack.
Subscribe and stay in the loop with the latest on Druid, Flink, and more!
Thank you for joining our newsletter!
Oops! Something went wrong while submitting the form.
Deep.BI needs the contact information you provide to contact you. You may unsubscribe at any time. For information on how to unsubscribe and more, please review our Privacy Policy.

.png)