
In large-scale analytics systems, mistakes in data ingestion or transformation can have long-lasting consequences, which makes the ability to restore earlier versions of data critical. Apache Druid addresses this through its segment versioning model.
Every piece of ingested data is stored as an immutable segment, and each time interval can have multiple segment versions. When new data is published, Druid doesn’t overwrite the old data; instead, it creates a higher version that shadows earlier ones. This mechanism ensures data consistency and enables quick rollback in cases such as incomplete or faulty ingestion jobs.
By marking segments as used or unused, or by re-registering them from deep storage, operators can precisely control which data is visible to queries. Understanding how Druid stores and versions segments is therefore key to building resilient ingestion pipelines and recovering quickly from operational errors.
Apache Druid’s versioning model works well for controlled updates, but it also means that mistakes during ingestion can lead to valid data being temporarily hidden. A common example arises when using MSQ for deduplication or ETL operations. If a query produces zero rows – for instance, because of an inverted time filter or an overly strict condition – no new data segments are generated. Even so, Druid updates the metadata by publishing empty tombstone segments and marking the previously active ones as unused.
Because newer tombstone versions automatically overshadow earlier data, the valid segments for that time chunk disappear from query results. To restore them, operators can mark the older segments back as used through the API, but only after the tombstones themselves have been marked unused. Otherwise, the empty segments continue to shadow the valid data.
In practice, recovery options depend on whether the segments still exist in Deep Storage:
Re-ingestion, however, is also compute-intensive since the data must be fully processed again before it becomes queryable.
Tested on Druid version 34.0.0
Ingest a sample data source (e.g., Wikipedia) and confirm the number of rows ingested.

Run the following SQL in the Druid web console:
SELECT "datasource", "segment_id", "start", "end", "version", "is_published", "is_active", "is_available"
FROM sys.segments
WHERE datasource = 'wikipedia'
Segment information can also be verified directly in the metadata store. For this article, we used Derby.

REPLACE INTO wikipedia
OVERWRITE WHERE __time >= TIMESTAMP '2016-06-27 00:00:00' AND __time < TIMESTAMP '2016-06-28 00:00:00'
SELECT
"__time",
"isRobot",
"channel",
"flags",
"isUnpatrolled",
"page",
"diffUrl",
"added",
"comment",
"commentLength",
"isNew",
"isMinor",
"delta",
"isAnonymous",
"user",
"deltaBucket",
"deleted",
"namespace",
"cityName",
"countryName",
"regionIsoCode",
"metroCode",
"countryIsoCode",
"regionName"
FROM wikipedia
WHERE __time >= TIMESTAMP '2016-06-27 00:00:00' AND __time < TIMESTAMP '2016-06-28 00:00:00' AND isRobot = 'xxx'
PARTITIONED BY DAY
CLUSTERED BY page
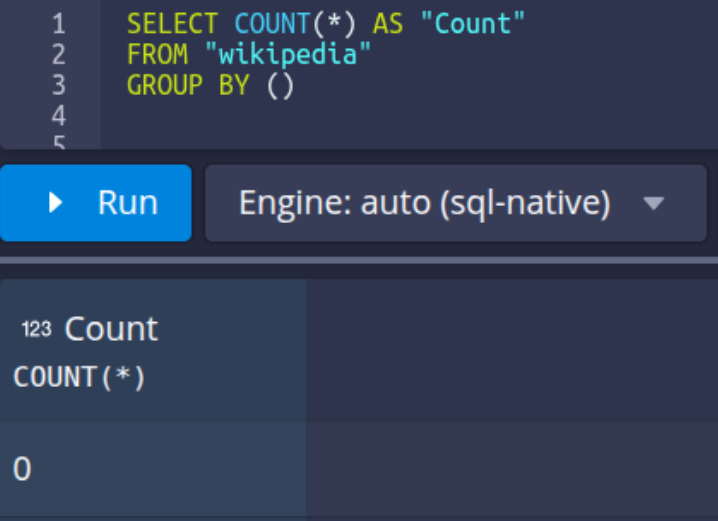
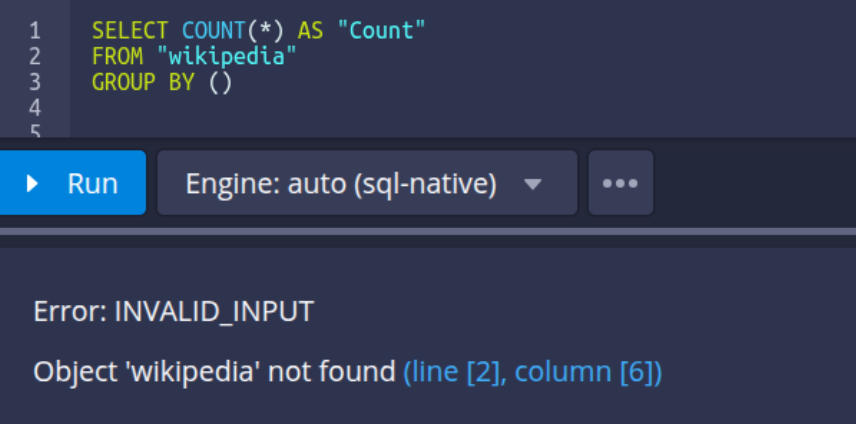
The above re-ingestion task will return zero rows, and subsequently, the system will report that the data source no longer exists (since this is the only interval associated with that data source). In practical scenarios, when only a portion of the data is re-indexed, the data source itself remains intact – only the data for the selected interval is affected.
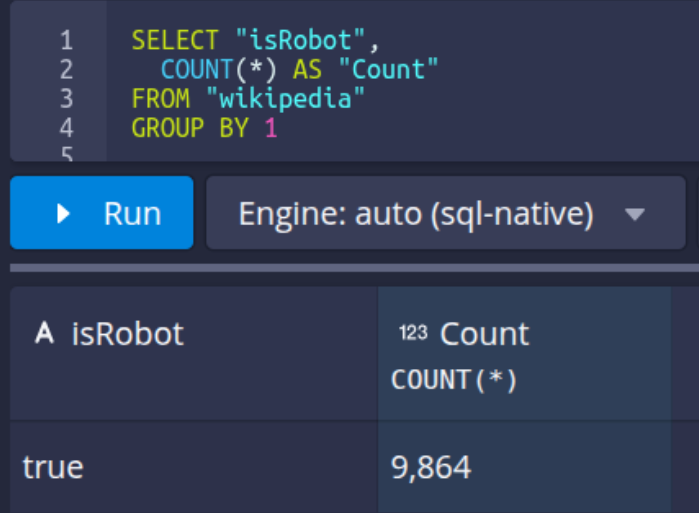
The view from the metadata store:

To restore version A instead of version B, simply marking version A as USED via the API is not sufficient. Druid will automatically revert it to UNUSED if a newer version (version B) remains active for the same time interval. By default, Druid always prefers the most recent segment version.
Therefore, to reinstate version A:
Note! Since Druid version 32.0.0 – coordinator APIs for marking segments as used or unused are now deprecated and will be removed in a future release. Use the corresponding Overlord APIs instead. For a full list, see New Overlord APIs.
DELETE /druid/indexer/v1/datasources/{dataSourceName}/segments/{segmentId}
Example:
curl --request DELETE "http://ROUTER_IP:ROUTER_PORT/druid/indexer/v1/datasources/wikipedia_hour/segments/wikipedia_hour_2015-09-12T16:00:00.000Z_2015-09-12T17:00:00.000Z_2023-08-10T04:12:03.860Z" \
--header 'Content-Type: application/json' \
--header 'Accept: application/json, text/plain'POST /druid/indexer/v1/datasources/{dataSourceName}/segments/{segmentId}
Example:
curl --request POST "http://ROUTER_IP:ROUTER_PORT/druid/indexer/v1/datasources/wikipedia_hour/segments/wikipedia_hour_2015-09-12T18:00:00.000Z_2015-09-12T19:00:00.000Z_2023-08-10T04:12:03.860Z" \
--header 'Content-Type: application/json' \
--header 'Accept: application/json, text/plain'REPLACE INTO wikipedia
OVERWRITE WHERE __time >= TIMESTAMP '2016-06-27 00:00:00' AND __time < TIMESTAMP '2016-06-28 00:00:00'
SELECT
"__time",
"isRobot",
"channel",
"flags",
"isUnpatrolled",
"page",
"diffUrl",
"added",
"comment",
"commentLength",
"isNew",
"isMinor",
"delta",
"isAnonymous",
"user",
"deltaBucket",
"deleted",
"namespace",
"cityName",
"countryName",
"regionIsoCode",
"metroCode",
"countryIsoCode",
"regionName"
FROM wikipedia
WHERE __time >= TIMESTAMP '2016-06-27 00:00:00' AND __time < TIMESTAMP '2016-06-28 00:00:00' AND isRobot = ‘true’
PARTITIONED BY DAY
CLUSTERED BY page
To confirm that the restoration was successful, run a SELECT query to ensure the expected data is visible.
{
"type": "kill",
"id": "kill-task-my-datasource",
"dataSource": "wikipedia",
"interval": "2016-06-27/2016-06-28"
}Restoring older segment versions in Apache Druid through the Data Management API is possible, but it is not risk-free. Keep the following considerations in mind:
Restore only time intervals that are no longer being modified (for example, through append or replace operations). Attempting to roll back segments for intervals still open to modification can lead to data loss or inconsistencies.
Only segment versions stored in Deep Storage and not removed by the auto-kill process can be recovered. Before initiating a restore, verify that auto-kill will not remove the target segments – for instance, by temporarily disabling it.
Manual rollbacks require a precise understanding of the ingestion history. Always validate the rollback process in a non-production environment before applying it to production data.
To ensure a safe restoration process:
Apache Druid’s segment versioning mechanism offers a powerful safeguard against ingestion errors – but it also introduces operational complexity. By understanding how to safely restore segment versions and manage metadata, engineers can recover quickly from issues while maintaining data consistency and system reliability.

